主要内容
- DDD基础理论
- 代码结构
DDD基础理论
领域驱动设计
参考书籍:
领域驱动设计精粹
领域驱动设计与模式实战
设计原则
- SRP(Single responsibility principle):单一职责原则,一个module只有一个原因修改
- OCP(Open/closed principle):开放-关闭原则,开放扩展,关闭修改
- LSP(Liskov substitution principle):里氏替换原则,子类型必须能够替换它们的基类型
- ISP(Interface segregation principle):接口隔离原则,你所依赖的必须是真正使用到的
- DIP(Dependency inversion principle):依赖导致原则,依赖接口而不是实现(高层不需要知道底层的实现)
模型演化
- 分层架构
系统按不同职责组织成有序层次,由于这种划分往往比较容易界定,也算是最常见和最受欢迎的一种架构,有一个说法是:“如果你不知道要用什么架构,那就用它。
MVC
缺点:
+ 底层是基础设施层, 领域层依赖于基础设施层
- 依赖倒置
依赖倒置的原则(DIP)由Robert C. Martin :
高层模块不应该依赖于底层模块,两者都应该依赖于抽象
抽象不应该依赖于实现细节,实现细节应该依赖于接口
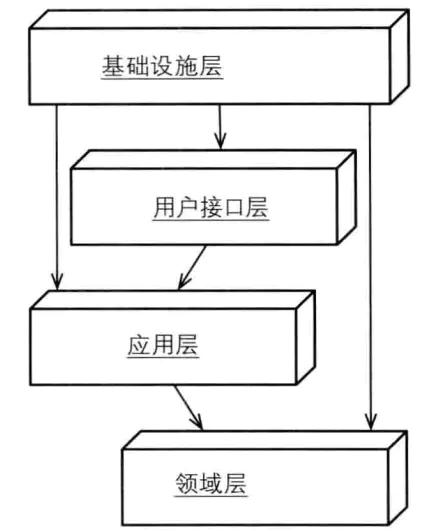
事实上已经没有分层概念了。无论高层还是底层,实际只依赖于抽象,整个分层好像被推平了。
- 六边形架构/整洁架构
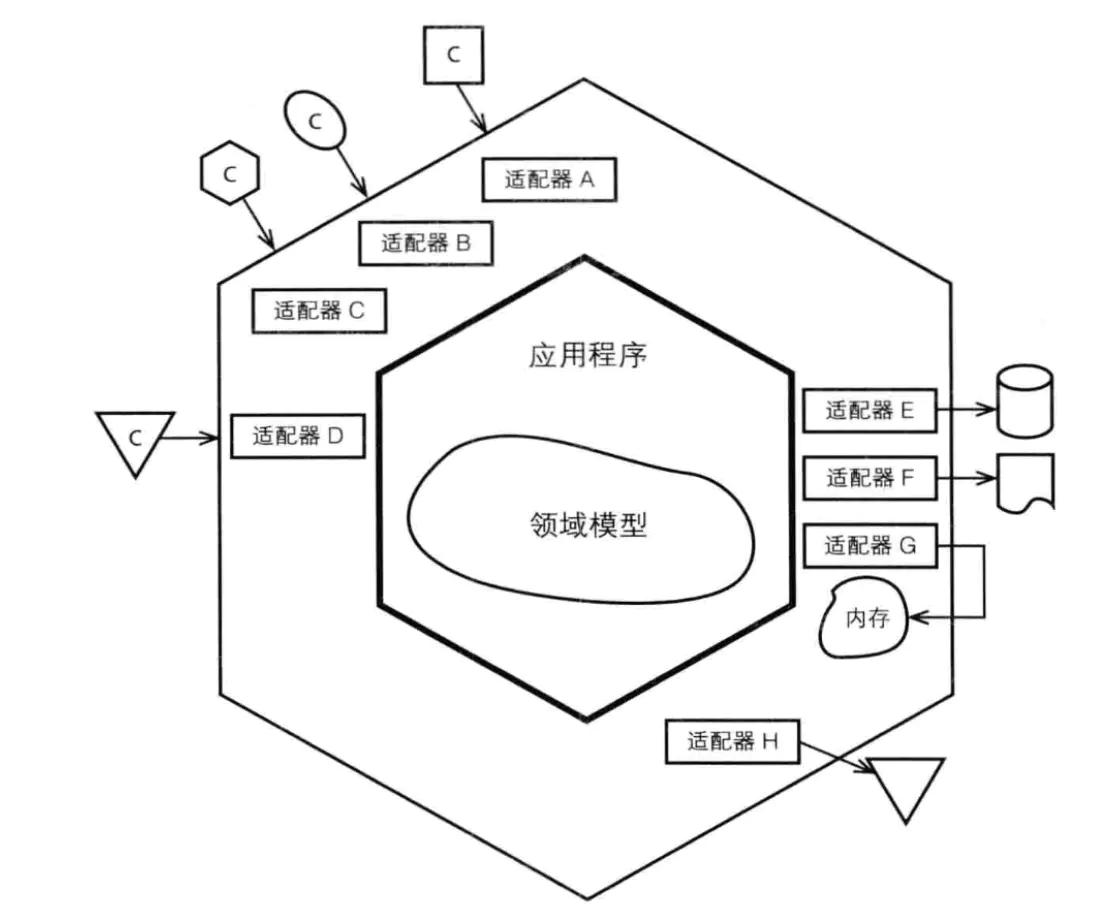
也是一种分层架构,只不过不是上下或左右,而是变成了内部和外部。
从外环到内环,软件的层级逐渐升高。
外环(low level)依赖内环(high level)。
代码结构
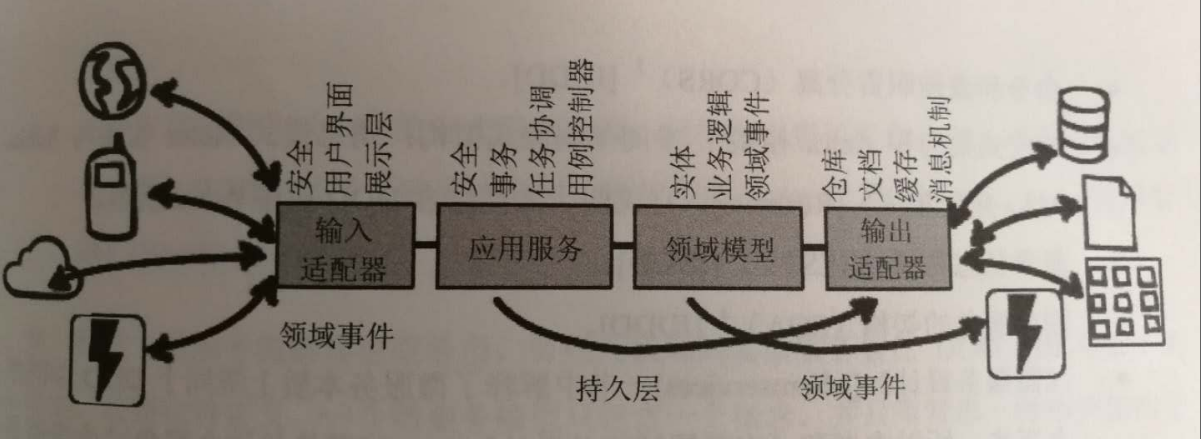
1 | DDD |
adapter 输出适配器
系统内部,具体技术实现;
仓库,文档,缓存,消息机制,领域事件发布/监听;
一般如下类型:
- persist
- message
- eventListener
api 输入适配器
- 对外接口,传统
controllerAPI层, 程序入口,客户端调用;
一般如下类型:
- controller
application 应用层
应用服务,传统 service 层, 一般跟场景(用例)有关。
一般如下类型:
- handler/service
- command 场景 POJO
一个场景(用例),对应一个command,对应一个handler
domain 领域层
一般如下类型:
- model 领域模型
- service 领域服务
- factory/builder 工厂
复杂对象构建, 比如 主键ID使用snow或美团leaf
model 领域模型层
一般如下类型:
- entity
- repository
- event
- 值对象
service 领域服务层
- 协调多个聚合,并且是领域逻辑,不放在应用服务层, 放在领域服务层
- 算法,策略,保持实体和值对象的单一原则,可以提炼出来变成领域服务
- 访问数据库等外部资源
方寸之间
领域服务
当领域遜辑放某-一个聚合里不合适,需要协调多个聚合,但由于是领域逻辑,放在应用服务里不合适的时候,可以放到领域服务里;
需要访问数据库等外部资源的业务逻辑,不建议聚合里,可以放到领域服务里
有些算法、策略代码,为了保持实体和值对象的职责单- - ,可以提炼出来变成领域服务( 领域服务类的命名不-定都要以Service结尾)
不涉及事务处理
富领域模型双刃剑
- 好处
分开对待本质复杂度和偶然复杂度,核心业务逻辑被封装在领域对象里,内聚,容易保持一致性, 且容易维护和扩展。
此外,容易测试,且代码和测试都可以作为文档。
- 坏处
对象引用多, 内存占用大, 影响吞吐量
通过聚合在贫富间取得平衡
聚合是一组相关领域模型的集合,是用来封装业务的不变性。同时强迫大家尽可能的简化领域模型之间的关联关系。在贫富之间寻找平衡。
聚合的主要原则包括:
聚合是-致性边界,聚合根负责执行业务规则,改变边界内的任一对象的状态都不能违反整个聚合的所有业务规则;
聚合根有全局标识,聚合边界内的其他实体只有局部标识,聚合边界外的对象,只能持有聚合根的
标识,不能引用聚合根对象,也不能持有聚合内部对象或标识聚合具有整体的生命周期,删除聚合根,聚合内的所有对象都需要删除
只有聚合根能从持久化系统内查询得到,边界内的对象只能从聚合根导航访问
聚合根和数据一致性
应用服务作为事务一致性边界,一个事务里不能涉及到两个聚合的修改,跨聚合的数据应该使用最终一致。
但最终一致性成本很高。
实例代码中,基于内存实现同步的领域事件发布和订阅。这样,实际上两个聚合根的更改基于同一个本地数据库事务。
但由于使用了事件驱动,在代码层面,两个聚合根的更新是解耦的,在需要最终一致性的时候容易重构。